

真实的智能一定是多模态的,听觉、视觉、触觉等共同参与了东谈主脑默契才略的造成。点击收听本新闻听新闻
国产AI,细致把视频生成拉进了有声电影期间。
自从Sora引爆视频生成之后,基本上统统AI生成的视频都属于“默片”的效力,也就是莫得对应的音效(防卫不是配乐)。
但现时,音效是不错径直自带了!而且照旧4K、60帧高清画质的那种。
那么AI视频生成现时能到什么水平?
咱们径直拿这个国产AI作念了个微电影,请看VCR:
翻开新闻客户端 升迁3倍运动度如何?是不是也曾有电影的阿谁feel了?
这个国产AI,恰是智谱刚升级的新清影,总体来看有三大特色:
电影级效力:除了刚才提到的4K、60帧高清以外,还守旧10秒时长和即兴比例视频。
模子才略全面升迁:背后的CogVideoX模子更懂复杂prompt,能够保捏东谈主物等主体的连贯性,效力更传神。
自带音效:引入CogSound模子,能够自动凭证视频试验生成匹配的音效,这个月将细致上线清言APP。
如斯一来,AI也曾具备了制作像上头这样微电影(或短视频)的全成分,而且在操作上也口角常浅易。
咱们先把一个主题“喂给”智谱清言的GLM 4 Plus,让它帮咱们生成微电影的剧本:

然后咱们再用文生图的AI,生成几张高清大图,以发轫片断为例,Prompt是这样的:
镜头从公园的鸟鸣和朝阳中逐步鼓舞,聚焦在一位满头鹤发的老爱妻身上。她坐在长椅上,手中拿着一册书,目光宁静而深切。

再参加新清影的图生视频界面,把这张图像传上去,并填写想要效力的prompt:
镜头从公园的鸟鸣和朝阳中逐步鼓舞,聚焦在一位满头鹤发的老爱妻身上。她坐在长椅上,逐步把书合上,望向迢遥堕入深念念。

接着不才方面采纳基础参数即可:
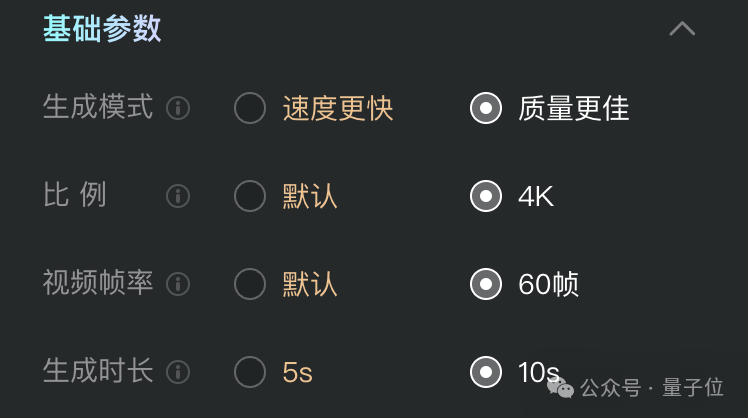
在静候霎时之后,一段电影级别、自带音效的高清视频片断就这样水汪汪的出生了。
重迭上头的技艺,咱们便不错获得后边的那些视频片断。
至于旁白部分,汲取的则是智谱在前不久刚发布的GLM-4-Voice情谊语音模子,不错作念到宛如真东谈主配音。
嗯,打得就是一套智谱的AI组合拳。
而梦想东谈主类从第一部无声电影(1895年)到第一部有声电影(1927年),足足滥用了32年。
如果从Sora算起,那么AI生成的视频从无声到有声,耗时只是9个月。
此时此刻,“AI一天,东谈主间一年”这句话,是真真儿的具象化了。
简约一段视频,秒出有声电影片断
那么智谱的CogSound模子还能hold住什么样的音效?
咱们这就来一波实测。
实测技艺也口角常浅易,咱们会截取电影中的视频片断四肢输入,磨真金不怕火的就是它能否对视频试验深入一语气,并生成莫得违和感的音效。
Round 1:当然环境
咱们先取一段雨天傍晚房间里的一个视频,把它“喂”给CogSound模子(注:以下原视频都是无声的),生成出来的音效是这样的:
翻开新闻客户端 升迁3倍运动度CogSound精确地get到了“下雨”这个要津元素,从音效上来看亦然毫无违和感。
再来观赏一段由清影生成、CogSound加音效的视频片断:
翻开新闻客户端 升迁3倍运动度Round 2:动物宇宙
咱们再来试试CogSound能否看视频识别搬动物的声息:
翻开新闻客户端 升迁3倍运动度CogSound不仅生成出了狮子姆妈低千里的叫声,也发觉到了它们处于当然环境之下,还配上了鸟鸣的声息。
Round 3:多种乐器
接下来,咱们上个难度,输入一段有多个乐器演奏的视一样段:
翻开新闻客户端 升迁3倍运动度不错看到,从视频一开动的画面来看,萨克斯这个乐器应当是“主角”,是以在乐器夹杂的音效中,萨克斯的声息是最大的。
而当萨克斯手使劲吹奏的时候,CogSound配的音效竟也有了音乐上的升沉,说真话,这小数如实是有点令东谈主有时。
但要非挑个问题的话,玩忽镜头在转向钢琴的时候,乐器的音效上,钢琴声息变大一些会更好些。
Round 4:科幻电影
终末,咱们再“喂”一个超等复杂的视频片断——《流浪地球》:
翻开新闻客户端 升迁3倍运动度讲真,期货配资若不是知谈这是CogSound生成的,许多东谈主应该都会以为它是电影原声了吧。
由此可见,无论“喂”给CogSound模子什么类型的视频,它都不错作念到对视频试验的精确一语气,况且给出对应音效。
除此以外,在视频本人生成的才略上,智谱的CogVideo也有了大幅的升迁。
举例生成的底下这位老爷爷,脸色和颜料的变化,宛如在看一个电影片断:
翻开新闻客户端 升迁3倍运动度还有像非常科幻的火焰老虎:
翻开新闻客户端 升迁3倍运动度而从上头两个例子中,咱们也不难发现,CogVideoX现时是不错守旧多种比例视频的生成。
那么接下来的问题就是:
若何作念到的?
最初是CogVideo的升级,主要纠合体现时了试验连贯性、可控性和老练效力等方面的才略升迁。
其举座的模子框架如下图所示,是基于多个民众Transformer模块,通过文本编码器将输入的文本升沉为潜在向量,再经由3D卷积和多层民众模块贬责,生成一语气的视频序列。

通盘历程可视为将当然谈话描写升沉为动态视觉试验的复杂系统。
在模子架构假想中,CogVideoX非常汲取了因果3D卷积(Causal 3D Convolution),以高效捕捉时空维度上的复杂变化,使得模子能够愈加精确地一语气和生成富余细节的场景。
同期,该模子引入了民众自稳当层归一化(AdaLN),通过动态转换不同模块的脾气,从而在视觉发达上竣事更当然、更具连贯性的视频生成。
为了应酬视频压缩与蓄意效力的挑战,CogVideoX汲取了3D VAE结构,通过对视频特征在空间和时候上的下采样,大幅镌汰了视频存储与蓄意支拨。

这意味着即便在资源有限的蓄意环境下,CogVideoX仍能生成高质料的视频试验,显耀升迁了其应用的可行性。
如果说CogVideoX负责生成可视的动态试验,那么CogSound则赋予这些画面以听觉上的生命。
CogSound是一种为无声视频自动生成音效的模子,能够基于视频试验智能合成配景音乐、对话音频及环境音效,其架构如下图所示:

CogSound的中枢时间依托于GLM-4V的多模态一语气才略,能够精确明白视频中的语义和情谊,并生成匹配的音效。
举例,在展示丛林景不雅的视频中,CogSound能够生成鸟鸣和风吹树叶的声息;而在城市街景中,则会生成车流与东谈主群的配景杂音。
为竣事这一宗旨,CogSound期骗了潜空间扩散模子(Latent Diffusion Model),通过将音频特征从高维空间进行压缩并再延长,从而灵验地生成复杂音效。
此外,CogSound通过块级时候对皆交叉防卫力(Block-wise Temporal Alignment Cross-attention)机制,确保生成的音频在时候维度和语义上与视频试验高度一致,幸免了传统音画合成中常见的错位和不合作问题。
这即是智谱CogVideoX才略升迁和CogSound背后的时间秘笈了。
短视频迈入了AI期间
多模态是通往AGI的必经之路。
这是智谱在很早之前便提议的一个默契,而跟着这次CogSound的发布,其多模态的矩阵可谓是再添一块拼图。
而它的多模态之路,不错追忆到2021年,具体到细节领域差异是:
文本生成(GLM)、图像生成(CogView)、视频生成(CogVideoX)、音效生成(CogSound)、音乐生成(CogMusic)、端对端语音(GLM-4-Voice)、自主代理(AutoGLM)。
若问这一步步走来,对现时的时间和行业带来了哪些改变,谜底玩忽是——
起码在短视频制作领域,是时候不错迈入AI期间了。
最初就是更高质料、更相宜物理宇宙次第的生成视频,在试验逻辑和视觉上基本上不错够到短视频制作的门槛。
加之CogVideoX还守旧绝裁夺的尺寸,更相宜用户在各式场景下的制作需求。
而最为要津的小数,跟着CogSound把视频生成拉进“有声电影”期间,使得输出的纵容不仅夸口了视觉的条目,更是相宜了真什物理宇宙中的听觉条目。
正如智谱所言:
真实的智能一定是多模态的,听觉、视觉、触觉等共同参与了东谈主脑默契才略的造成。
据悉,CogSound行将在智谱清言上线,而且智谱还将发布音乐模子CogMusic。
加之此前也曾发布的GLM-4-Voice东谈主声模子,智谱不错说是把视频生成中的“音”这块全面hold住。
一言以蔽之,现时作念短视频,玩忽就成了有想法就能竣事的事儿了。
想体验的小伙伴,不错点击文末阅读原文学验下哦~